
We present AEStream: a library to efficiently process event-based data from neuromorphic sensors with a dead-simple interface. We show that AEStream can double the throughput across synchronization barriers and exploit the parallelism of the GPU to process 1.3 times more data with 5 times fewer memory operations. AEStream supports files, event-based camera, and network input and streams to file, network, and GPUs via PyTorch. All code is open-source, installable via pip and easily extensible.
Preprint: http://arxiv.org/abs/2212.10719
Introduction: the problem with processing events

Neuromorphic sensors imitate the sparse and event-based communication seen in biological sensory organs and brains. Today's sensors can emit many millions of asynchronous events per second. For modern computers to cope with that they need to process events in parallel. Unfortunately, that requires synchronization mechanisms between threads and processes which takes up a large part of our processes.
Panel (A) in the figure above illustrates the problem: every time an input thread passes over some work, time is spent to coordinate the work. Because of this cost, threads typically bundle events into buffers to amortize the cost. Panel (B) shows another method that do not require memory locks and that can operate directly on events: coroutines.
Coroutines were designed in 1958 as a way to pass control between functions, without the need for centralized synchronization. In theory, this means that coroutines on multicore systems can maximize core utilization without the overhead of locks. We set out to test that.
Benchmarking event throughput with coroutines
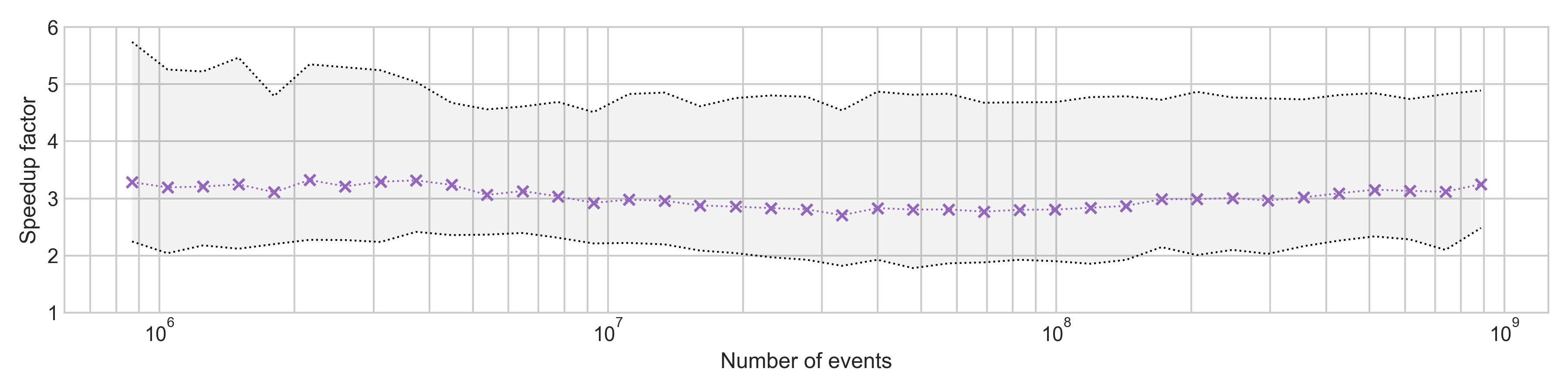
To measure the actual impact of coroutines on processing performance, we devised a benchmark comparing coroutines to conventional thread programming. The computational work in the benchmark is trivial to isolate the effect of the synchronization between threads. Our benchmark is promising: coroutines provide at last 2 times higher throughput compared to conventional threads, irrespective of buffer sizes and number of threads.
AEStream: Accelerated event-based processing
We built on the above results to construct a library to efficiently process event-based data: AEStream. AEStream uses simple address-event representations (AER) and supports reading from file, event-based cameras, and from the network.
AEStream has a straight-forward command-line (CLI) interface where any inputs can be combined with any outputs.
$ aestream input inivation dvx output udp 10.0.0.1
$ aestream input file f.aedat4 output stdout
AEStream is written in C++ and CUDA, but can be operated from Python.
The example to the right demonstrates how a USB camera with 640x480 resolution can be read.
The .read() operation extracts a PyTorch tensor that can be directly applied to neural
networks, including
spiking neural networks with the
neuron simulator, Norse.
import aestream
with aestream.USBInput((640, 480)) as stream:
while True:
tensor = stream.read()

Benchmarking GPU processing with AEStream
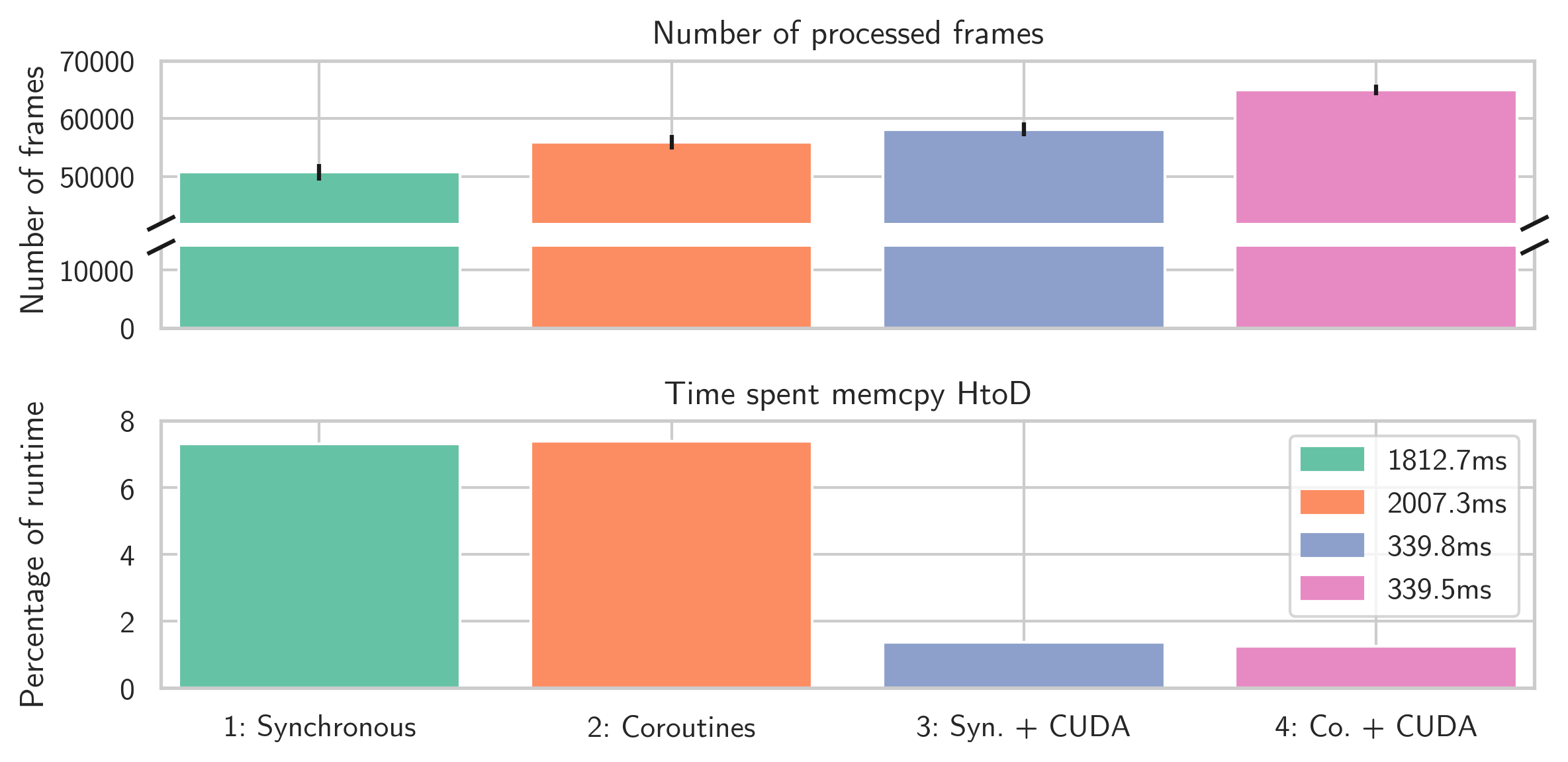
- Synchronous read-and-copy events to GPU.
- Concurrent read-and-copy events to GPU with coroutines.
- Synchronous read-and-copy events with parallel copy to CUDA.
- Concurrent read-and-copy events with parallel copy to CUDA.
In sum, AEStream reduces copying operations to the GPU by a factor of at least 5 and allows processing at around 30% more frames (6.5 × 104 versus 5 × 104 in total) over a period of around 25 seconds compared to conventional synchronous processing.
Discussion
We have demonstrated the efficiency of AEStream for event-based processing in CPU and from CPU to peripherals (GPU). Because AEStream is built around simple, functional primitives, it can arbitrarily connect inputs to outputs in a straight-forward Python or command-line interface. This is particularly useful for real-time settings with dedicated, parallel or neuromorphic hardware. Another important contribution is the PyTorch and CUDA support. Low-level CUDA programming is a non-trivial and error-prone endeavor that is rarely worth the effort. In the case of GPU-integration, however, we believe the effort is timely; efficiently sending AER data to GPUs opens the door to a host of contemporary machine learning tools, ranging from deep learning libraries like PyTorch to spiking neuron simulators like Norse to graphical libraries for visual inspection. It should be said that we have not studied AEStream in relation to other libraries, so we can only hypothesize how fast or slow it performs in comparison. Further benchmarks in this direction would be interesting.
Finally, it is our hope that AEStream can benefit the community and lower the entrance-barrier for research in neuromorphic computation. This website publishes all our code, along with instructions on how to reproduce our results. We encourage the reader to copy and extend our work.
Acknowledgements
We foremost would like to thank Anders Bo Sørensen for his friendly and invaluable help with CUDA and GPU profiling. Emil Jansson deserves our gratitude for scrutinizing and improving the coroutine benchmark C++ code. We gracefully recognize funding from the EC Horizon 2020 Framework Programme under Grant Agreements 785907 and 945539 (HBP). Our thanks also extend to the Pioneer Centre for AI, under the Danish National Research Foundation grant number P1, for hosting us.